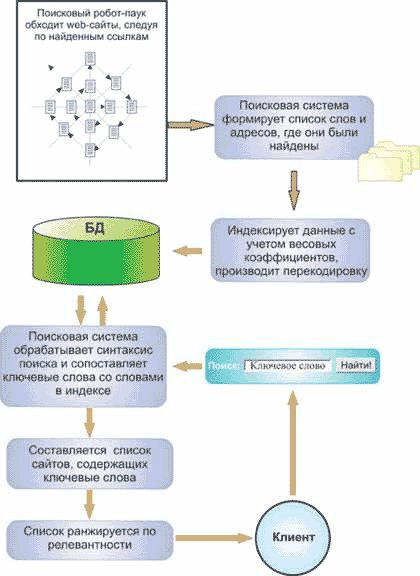
Схема построения индекса показана ниже. Сетевые агенты, или роботы-пауки, "ползают" по Сети, анализируют содержимое Web-страниц и собирают информацию о том, что и на какой странице было обнаружено.
 При нахождении очередной HTML-страницы большинство поисковых систем фиксируют
слова, картинки, ссылки и другие элементы (в разных поисковых системах
по-разному), содержащиеся на ней. Причем при отслеживании слов на странице
фиксируется не только их наличие, но и местоположение, т.е. где эти слова
находятся: в заголовке (title), подзаголовках (subtitles), в метатэгах (meta
tags, метатэги - это служебные тэги, позволяющие разработчикам помещать на
Web-страницы служебную информацию, в том числе для того, чтобы сориентировать
поисковую машину.) или в других местах. При этом обычно фиксируются значимые
слова, а союзы и междометия типа "а", "но" и "или"
игнорируются. Метатэги позволяют владельцам страниц определить ключевые слова и
тематику, по которым индексируется страница. Это может быть актуально в случае,
когда ключевые слова имеют несколько значений. Метатэги могут сориентировать
поисковую систему при выборе из нескольких значений слова на единственно
правильное. Однако метатэги
работают надежно только в том
случае, когда заполняются честными владельцами сайта. Недобросовестные владельцы
Web-сайтов помещают в свои метатэги наиболее популярные в Сети слова, не имеющие
ничего общего с темой сайта. В результате посетители попадают на незапрашиваемые
сайты, повышая тем самым их рейтинг. Именно поэтому многие современные
поисковики либо игнорируют метатэги, либо считают их дополнительными по
отношению к тексту страницы. Каждый робот поддерживает свой список ресурсов,
наказанных за недобросовестную рекламу.
При нахождении очередной HTML-страницы большинство поисковых систем фиксируют
слова, картинки, ссылки и другие элементы (в разных поисковых системах
по-разному), содержащиеся на ней. Причем при отслеживании слов на странице
фиксируется не только их наличие, но и местоположение, т.е. где эти слова
находятся: в заголовке (title), подзаголовках (subtitles), в метатэгах (meta
tags, метатэги - это служебные тэги, позволяющие разработчикам помещать на
Web-страницы служебную информацию, в том числе для того, чтобы сориентировать
поисковую машину.) или в других местах. При этом обычно фиксируются значимые
слова, а союзы и междометия типа "а", "но" и "или"
игнорируются. Метатэги позволяют владельцам страниц определить ключевые слова и
тематику, по которым индексируется страница. Это может быть актуально в случае,
когда ключевые слова имеют несколько значений. Метатэги могут сориентировать
поисковую систему при выборе из нескольких значений слова на единственно
правильное. Однако метатэги
работают надежно только в том
случае, когда заполняются честными владельцами сайта. Недобросовестные владельцы
Web-сайтов помещают в свои метатэги наиболее популярные в Сети слова, не имеющие
ничего общего с темой сайта. В результате посетители попадают на незапрашиваемые
сайты, повышая тем самым их рейтинг. Именно поэтому многие современные
поисковики либо игнорируют метатэги, либо считают их дополнительными по
отношению к тексту страницы. Каждый робот поддерживает свой список ресурсов,
наказанных за недобросовестную рекламу.
Очевидно, что если вы ищете сайты по ключевому слову "собака", то поисковый механизм должен найти не просто все страницы, где упоминается слово "собака", а те, где это слово имеет отношение к теме сайта. Для того чтобы определить, в какой степени то или иное слово имеет отношение к профилю некоторой Web-страницы, необходимо оценить, насколько часто оно встречается на странице, есть ли по данному слову ссылки на другие страницы или нет. Короче говоря, необходимо ранжировать найденные на странице слова по степени важности. Словам присваиваются весовые коэффициенты в зависимости от того, сколько раз и где они встречаются (в заголовке страницы, в начале или в конце страницы, в ссылке, в метатэге и т.п.). Каждый поисковый механизм имеет свой алгоритм присваивания весовых коэффициентов - это одна из причин, по которой поисковые машины по одному и тому же ключевому слову выдают различные списки ресурсов. Поскольку страницы постоянно обновляются, процесс индексирования должен выполняться постоянно. Роботы-пауки путешествуют по ссылкам и формируют файл, содержащий индекс, который может быть довольно большим. Для уменьшения его размеров прибегают к минимизации объема информации и сжатию файла. Имея несколько роботов, поисковая система может обрабатывать сотни страниц в секунду. Сегодня мощные поисковые машины хранят сотни миллионов страниц и получают десятки миллионов запросов ежедневно.
При построении индекса решается также задача снижения количества дубликатов - задача нетривиальная, учитывая, что для корректного сравнения нужно сначала определить кодировку документа. Еще более сложной задачей является отделение очень похожих документов (их называют "почти дубликаты"), например таких, в которых отличается лишь заголовок, а текст дублируется. Подобных документов в Сети очень много - например, кто-то списал реферат и опубликовал его на сайте за своей подписью. Современные поисковые системы позволяют решать подобные проблемы.
(1) Сетевые агенты или роботы ползают по сети, анализируют содержимое страниц и собирают информацию, что и на какой странице находится.
При нахождении очередной страницы поисковая система фиксирует слова, картинки, ссылки содержащиеся на ней.
(2) Поисковая система формирует список слов и адресов, где они были найдены.
(3) Данные индексируются с учетом весовых коэффициентов, производится их перекодировка.
Ища сайт по слову кошка, поисковый механизм должен найти не просто все страницы где есть слово кошка, а тем, где это слово имеет отношение к теме сайта. Для того, чтобы определить, насколько то или иное слово имеет отношение к профилю некоторой страницы, необходимо оценить, насколько часто оно встречается на странице, есть ли по данному слову ссылки. Надо ранжировать найденные на странице слова по степени важности. Словам присваиваются весовые коэффициенты в зависимости от того, сколько раз и где они встречаются (в заголовке, в конце или начале, в ссылке, в метатэге).
(4) Созданный индекс сохраняется в БД, которая постоянно обновляется.
(5) Поиск по индексу заключается в том, что пользователь формирует запрос и передает его поисковой машине.
При запросе используются булевы операторы: AND, OR, NOT
(6) Поисковая система обрабатывает синтаксис запроса и, сравнивает ключевые слова со словами в индексе.
(7) Составляется список сайтов содержащих ключевые слова.
(8) Список ранжируется по релевантности
(9) Формируется результат поиска