До последнего времени никто не владел полной информацией об архитектуре Web-пространства. А именно эти сведения крайне важны для достижения, с одной стороны, эффективного охвата информационных ресурсов средствами информационно-поисковых систем, а с другой стороны (со стороны пользователя), для обеспечения возможности получения действительно необходимой информации из Cети.
Близкой к реальности математической модели не существовало вплоть до 2000 года. Лишь в этом году специалисты компаний AltaVista, IBM и Compaq (руководитель Института поиска и анализа текстов (IBM) Андрей Бредер Broder) совершили прорыв, математически описав "карту" ресурсов и гиперсвязей существующего пространства World Wide Web. Исследования опровергли расхожее мнение, будто Интернет - это единое цельное пространство. Проследив с помощью поискового механизма AltaVista свыше 600 млн. Web-страниц и 1,5 млрд. ссылок, размещенных на этих страницах, ученые пришли к выводу о том, что топология Web-пространства соответствует модели "галстука-бабочки" (Bow Tie), в которой вершины соответсвуют страницам, а ребра соединяющим страницы гиперссылкам состоящей из следующих компонентов:
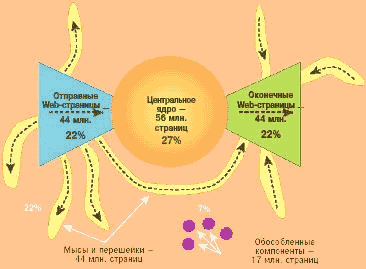
центральное ядро (SCC), или узел галстука, составляют Web-страницы, взаимо-связанные так тесно, что, следуя гиперссылкам, c каждой из них в конечном счете можно попасть на любую другую (27%);
22% Web-страниц - это "отправные Web-страницы" IN. Они содержат гиперссылки, которые в конечном счете ведут к ядру, но из ядра к ним попасть нельзя;
еще столько же (22%) - "оконечные Web-страницы" OUT, к которым можно прийти по ссылкам из ядра, но нельзя вернуться назад;
22% Web-страниц полностью изолированы от центрального ядра: это либо "мысы", связанные гиперссылками со страницами любой другой категории, либо "перешейки", соединяющие две Web-страницы, не входящие в ядро;
7% страниц представляют "изолированные острова", которые вообще не пересекаются с остальными ресурсами Интернета. Единственный способ обнаружить ресурсы этой группы - напрямую знать адреса. Никакие поисковые машины не смогут найти эти острова, если они в прошлом каким-то образом не соединялись с другими частями Интернета.
Исследователи обнаружили, что пропорции этих категорий в течении месяцев оставались неизменными, несмотря на увеличение общего объема ресурсов.
Если между двумя случайными страницами есть связь, то среднее количество переходов составляет 16. А если этот путь двухсторонний, то среднее число промежуточных щелчков будет 7.
Топология и характеристики модели оказались одинаковыми для различных подмножеств web-пространства, что подтверждает то, что web это фрактал., то есть свойство структуры Bow Tie всего пространства также верны и для его отдельных подмножеств. То есть алгоритмы использующие информацию о структуре web-пространства предположительно будет работать и на отдельных его подмножествах.
Информация о структуре web-пространства уже используется при решении многих задач, например, оптимизации эффективности механизмов сканирования, при анализе и прогнозе его развития, при построении новых web-сервисов.
Топология Bow Tie поясняет динамический характер Сети и позволяет получить представление о некоторых особенностях сложной организации WWW. В последнее время в связи с этим исследованием появились идеи построения нетрадиционных средств "обратной навигации" в Сети, реализующие, например, переходы с Web-сайта на те Web-ресурсы, с которых имеются ссылки на него. Эта технология позволила бы находить новую информацию на основании "оконечных Web-страниц" модели Bow Tie. А именно такими страницами зачастую оказываются научные статьи, рефераты или отчеты о научно-технических работах.
С точки зрения обновляемости информации, все Интернет-пространство можно условно разделить на две составляющие: стабильную и динамическую. Стабильная составляющая содержит информацию "долговременного" плана, например монографии, галереи, коллекции или архивы. Динамическая составляющая включает постоянно обновляемые или новые ресурсы. Небольшая часть этой составляющей вливается затем в стабильную, в то время как большая часть "исчезает" из Сети.
В свою очередь, информационные потребности пользователей можно условно разделить на две части - "знания и понятия" и "новости". Очевидно, что первая часть потребностей в большей мере удовлетворяется стабильной составляющей Интернета, в то время как потребности в новостях могут найти свое удовлетворение только в динамической составляющей New Media.